Energy Efficient Autonomous Systems and Robotics



Software and Hardware Deployment in Real-world Autonomous Environments
My team has a great experience in working with several software environments as well as low power and autonomous hardware system integration, examples shown in the figure. I have a longstanding collaboration through funded projects with the researchers at US Army Research Lab. This collaboration has resulted in creating ARL Crazyflie Swarm laboratory that can accommodate 20 Crazyflie drones. I have a smaller version in my lab in which we could demonstrate our work. I also use four other multi- agent environments that provide different challenges, configurations and heterogeneity to evaluate my research in an autonomous environment. These include the Donkey Car simulator and the car kit, and the JetBot car kit from Nvidia, StarCraft II, MiniGrid Env, MiniWorld Env, Ai2Thor and iGibson Indoor navigation environment, MultiWorld robotic manipulation environment based on Mujoco. We have successfully demonstrated the feasibility of our proposed research techniques with Crazyflie drones and Donkey Car and JetBot that have embedded Nvidia Jetson CPU and GPU.

A Binarized and Terrorized EdgeAI Autoencoder Accelerator for Reinforcement Learning
This ARL funded project aims at designing low power techniques for EdgeAI embedded devices that use reinforcement learning (RL). Convolutional autoencoders (AEs) have demonstrated great improvement for speeding up the policy learning time when attached to the RL agent, by compressing the high dimensional input data into a small latent representation for feeding the RL agent. Despite reducing the policy learning time, AE adds a significant computational and memory complexity to the model which contributes to the increase in the total computation and the model size. In this work, we proposed a binary and ternary precision AE model for speeding up the policy learning process of RL agent while reducing the complexity overhead without deteriorating the policy that an RL agent learns. Binary Neural Networks (BNNs) and Ternary Neural Networks (TNNs) compress weights into 1 and 2 bits representations, which result in significant compression of the model size and memory as well as simplifying multiply-accumulate (MAC) operations into 1-bit or 2-bit operation. We evaluated the performance of our model in three autonomous environments including DonkeyCar, Miniworld sidewalk, and Miniworld Object Pickup, which emulate various real-world applications with different levels of complexity. With proper hyperparameter optimization and architecture exploration, TNN models achieve near the same average reward, Peak Signal to Noise Ratio (PSNR) and Mean Squared Error (MSE) performance as the full-precision model while reducing the model size by 10x compared to full-precision and 3x compared to BNNs. However, in BNN models the average reward drops up to 12% - 25% compared to the full-precision even after increasing its model size by 4x. We also designed and implemented a scalable hardware accelerator which is configurable in terms of the number of processing elements (PEs) and memory data width to achieve the best power, performance, and energy efficiency trade-off for EdgeAI embedded devices. The proposed hardware implemented on Artix-7 FPGA dissipates 250 uJ energy while meeting 30 frames per second (FPS) throughput requirements. The hardware is configurable to reach an efficiency of over 1 TOP/J on FPGA implementation. The proposed hardware accelerator was synthesized and placed-and-routed in 14 nm FinFET ASIC technology which brings down the power dissipation to 3.9 uJ and maximum throughput of 1,250 FPS. Compared to the state of the art TNN implementations on the same target platform, our hardware is 5x and 4.4x more energy efficient on FPGA and ASIC, respectively [J27].


Context Reasoning and Relational Reinforcement Learning for Multi-Agent Teaming
This recently DARPA collaborative funded project aims to develop the foundations for a new approach to multi-agent teaming that (1) is feasible with limited communication, compute resources, and power, (2) enables flexible local reasoning and decision-making based on rich, declarative representations of context and commander’s intent, and (3) yields teams that respond well to unexpected opportunities and challenges. Our approach to these challenges involves exploring new techniques by introducing deep relational reinforcement learning, hierarchical reinforcement learning, knowledge base and reasoning techniques to improve learning from complex environments. In RL, it is essential to reduce the number of samples and actions taken by the AI agent in the real world and minimize the compute-intensive policy learning process. Furthermore, in neural network architectures, the model size and computation complexity are two important factors governing storage, throughput and energy efficiency when deployed for inference. In [T11, T12, T1] and [J26,C71,C62], we have shown by adding hierarchical learning and structured guidance to reinforcement learning AI agents we can significantly speed up the policy learning time and efficiency to learn complex real-world environments.
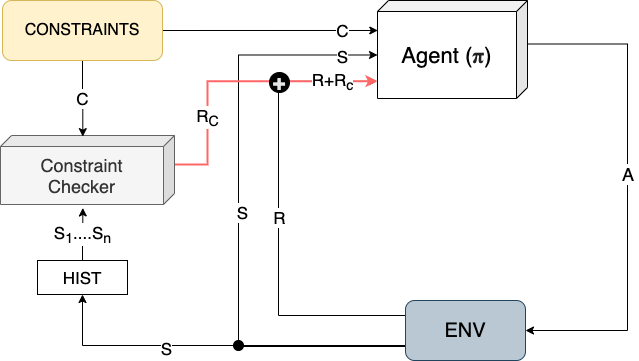
Guiding Safe Reinforcement Learning Policies Using Structured Language Constraints
Reinforcement learning (RL) has shown success in solving complex sequential decision making tasks when a well defined reward function is available. For agents acting in the real world, these reward functions need to be designed very carefully to make sure the agents act in a safe manner. This is especially true when these agents need to interact with humans and perform tasks in such settings. However, hand-crafting such a reward function often requires specialized expertise and quickly becomes difficult to scale with task-complexity. This leads to the long-standing problem in reinforcement learning known as reward sparsity where sparse or poorly specified reward functions slow down the learning process and lead to sub-optimal policies and unsafe behaviors. To make matters worse, reward functions often need to be adjusted or re-specified for each task the RL agent must learn. On the other-hand, it’s relatively easy for people to specify using language what you should or shouldn’t do in order to do a task safely. Inspired by this, we propose a framework to train RL agents conditioned on constraints that are in the form of structured language, thus reducing effort to design and integrate specialized rewards into the environment. In our experiments, we show that this method can be used to ground the language to behaviors and enable the agent to solve tasks while following the constraints. We also show how the agent can transfer these skills to other tasks.
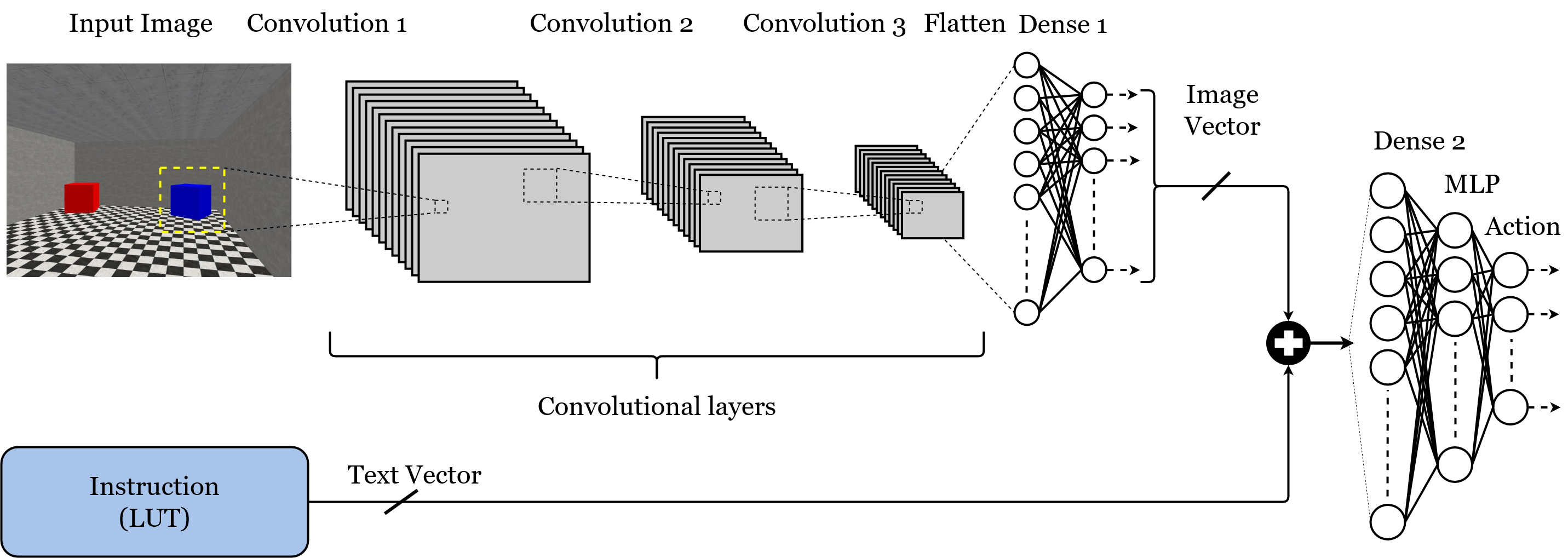
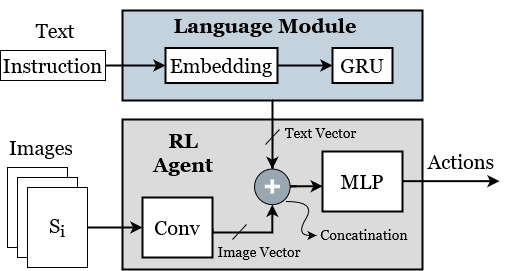
Energy-Efficient Hardware for Language Guided Reinforcement Learning
Reinforcement learning (RL) has shown great performance in solving sequential decision-making problems. While a lot of works have done on processing state information such as images, there has been some effort towards integrating natural language instructions into RL. In this research, we propose an energy-efficient architecture which is designed to receive both images and text inputs as a step towards designing RL agents that can understand human language and actin real-world environments. Different configurations are proposed to illustrate the trade-off between the number of parameters and the model accuracy, and a custom low power hardware is designed and implemented on FPGA based on the best configuration. The hardware designed to be configurable with different parameters such as the number of processing elements, so that it can easily balance power and performance. The high throughput configuration achieves 217 frames per second throughput with 1.2 mJ energy consumption per classification on Xilinx Artix-7 FPGA, while the low-power configuration consumes less than 139 mW for 30 frames per second classification. Compared to similar works using FPGA for hardware implementation, our design is more energy-efficient and needs less energy for generating each output.